[공부 자료 : Must Have 데싸노트의 실전에서 통하는 머신러닝]
# Pandas vs. Numpy
- Pandas : 사람이 읽기 쉬운 형태의 자료구조를 제공
종류 : Pandas series (col이 하나), Pandas DataFrame (col이 둘 이상)
입출력 : SQL, 엑셀, CSV, 데이터베이스
장점 : 하나 이상의 자료형을 원소로 가질 수 있다
테이블 형식의 작업(SQL과 같은 쿼리나 조인)이 가능
단점 : 2차원 이하 배열의 데이터까지 가능
메모리가 상대적으로 많이 필요
속도가 느림
- Numpy : 컴퓨터가 계산하기 좋은 형태의 자료구조를 제공 (col 이름이 없다)
입출력 : npv, npz, txt
연산 : 행렬 및 벡터 연산 기반
장점 : 3차원 이상의 배열도 가능
메모리가 상대적으로 조금 필요
속도가 빠름
단점 : 같은 자료형만 원소로 가질 수 있음
# Pandas 다루기
- 데이터 가져오기
read_csv( ) : Pandas로 csv 파일 불러오기
import pandas as pd
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/sample.csv'
sample = pd.read_csv(file_url)
sample
head( ) : 상위 5개 인덱스만 출력
sample.head() # 상위 5개 인덱스 출력
sample.head(3) # 상위 3개 인덱스 출력tail( ) : 하위 5개 인덱스만 출력
sample.tail() # 하위 5개 인덱스 출력
sample.tail(10) # 하위 10개 인덱스 출력info( ) : 데이터 요약 정보
RangeIndex : 데이터 행 수
entries : 인덱스 번호
Datacolums : 변수 개수
Column : 변수명
Non-Null Count : Null이 아닌 데이터 수
Dtype : 자료형
sample.info()
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Var_1 19 non-null int64
# 1 Var_2 19 non-null int64Pandas 주요 자료형
object : 문자열
int64 : 소수점 없는 숫자
float64 : 소수점 있는 숫자
bool : 불리언
datetime64 : 날짜/시간
describe( ) : col별 데이터 통계 정보
count : 데이터 개수
mean : 평균
std : 표준편차
min, max : 최솟값, 최댓값
25%, 50%, 75% : 사분위수
sample.describe()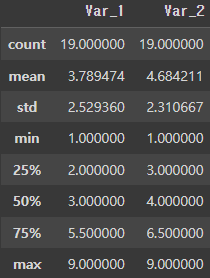
- DataFrame 다루기
pd.DataFrame( ) : DataFrame 직접 만들기
# Dictionary -> DataFrame
sample_dic = {'name' : ['kim', 'lee', 'park'], 'age' : [23, 22, 21]}
pd.DataFrame(sample_dic)
# name age
# 0 kim 23
# 1 lee 22
# 2 park 21pd.DataFrame(리스트, columns = [col_1, col_2, ...], index = [row_1, row_2, ...]) :
# List -> DataFrame
sample_list = [[1, 2], [3, 4], [5, 6], [7, 8]]
pd.DataFrame(sample_list, columns = ['var_1', 'var_2'], index = ['a', 'b', 'c', 'd'])
# var_1 var_2
# a 1 2
# b 3 4
# c 5 6
# d 7 8DataFrame['col명 '] : DataFrame col 기준 인덱싱
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/sample_df.csv'
sample_df = pd.read_csv(file_url, index_col = 0) # index_col = 0 : 0번째 col을 index로 지정
sample_df
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5
# col 1개 인덱싱
sample_df['var_1'] # 한 줄 데이터 = Pandas Series
# a 2
# b 4
# c 5
# d 1
# e 4
# f 5
# g 7
# h 8
# i 2
# j 9
# col 2개 인덱싱
sample_df[['var_1', 'var_2']] # 얘는 Pandas DataFrame
# var_1 var_2
# a 2 2
# b 4 3
# c 5 4
# d 1 4
# e 4 5
# f 5 4
# g 7 5
# h 8 8
# i 2 3
# j 9 3DataFrame.loc['index 명'] : DataFrame row index 이름 기준 인덱싱
sample_df
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5
# row 1개 인덱싱
sample_df.loc['a']
# var_1 2
# var_2 2
# var_3 1
# var_4 4
# var_5 3
# row 3개 인덱싱
sample_df.loc[['a', 'b', 'c']]
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# row 3개 인덱싱
sample_df.loc['a':'c'] # 'a' row 이상, 'c' row 이하
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5DataFrame.iloc[index 번호] : DataFrame row 번호 기준 인덱싱
sample_df
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5
sample_df.iloc[[0, 1, 2]]
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
sample_df.iloc[0:2] # 0번 row 이상, 2번 row 미만
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1DataFrame.iloc[index 번호, col 번호] : Dataframe row & col 인덱싱
sample_df.iloc[0:3, 2:4] # [0번 row(a) 이상, 3번(d) row 미만] & [2번 col(var_3) 이상, 4번 col(var_5) 미만]
# var_3 var_4
# a 1 4
# b 3 7
# c 6 3DataFrame.drop('index 명') : row 삭제
# 'a' row 삭제
sample_df.drop('a')
# var_1 var_2 var_3 var_4 var_5
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5
# 'a', 'b' row 삭제
sample_df.drop(['a', 'b'])
# var_1 var_2 var_3 var_4 var_5
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5
sample_df # 원본은 변화가 없다
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5DataFrame.drop('col 명', axis = 1) : col 삭제
# 'var_1' col 삭제
sample_df.drop('var_1', axis = 1)
# var_2 var_3 var_4 var_5
# a 2 1 4 3
# b 3 3 7 1
# c 4 6 3 5
# d 4 5 6 7
# e 5 7 8 3
# f 4 8 9 4
# g 5 2 0 6
# h 8 1 7 8
# i 3 5 2 1
# j 3 7 6 5
# 'var_1', 'var_2 col' 삭제
sample_df.drop(['var_1', 'var_2'], axis = 1)
# var_3 var_4 var_5
# a 1 4 3
# b 3 7 1
# c 6 3 5
# d 5 6 7
# e 7 8 3
# f 8 9 4
# g 2 0 6
# h 1 7 8
# i 5 2 1
# j 7 6 5
sample_df # 원본은 변화가 없다DataFrame.reset_index( ) : 현재 index를 변수(col)로 빼내기
새로운 index에는 0부터 번호를 부여
sample_df.reset_index()
# index var_1 var_2 var_3 var_4 var_5
# 0 a 2 2 1 4 3
# 1 b 4 3 3 7 1
# 2 c 5 4 6 3 5
# 3 d 1 4 5 6 7
# 4 e 4 5 7 8 3
# 5 f 5 4 8 9 4
# 6 g 7 5 2 0 6
# 7 h 8 8 1 7 8
# 8 i 2 3 5 2 1
# 9 j 9 3 7 6 5
sample_df # 원본은 변화가 없다
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5DataFrame.reset_index(drop = True) : 현재 index를 삭제하기
sample_df.reset_index(drop = True)
# var_1 var_2 var_3 var_4 var_5
# 0 2 2 1 4 3
# 1 4 3 3 7 1
# 2 5 4 6 3 5
# 3 1 4 5 6 7
# 4 4 5 7 8 3
# 5 5 4 8 9 4
# 6 7 5 2 0 6
# 7 8 8 1 7 8
# 8 2 3 5 2 1
# 9 9 3 7 6 5
sample_df # 원본은 변화가
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5DataFrame.set_index('col 명') : 기존 변수(col)을 index로 설정하기
sample_df.set_index('var_1')
# var_2 var_3 var_4 var_5
# var_1
# 2 2 1 4 3
# 4 3 3 7 1
# 5 4 6 3 5
# 1 4 5 6 7
# 4 5 7 8 3
# 5 4 8 9 4
# 7 5 2 0 6
# 8 8 1 7 8
# 2 3 5 2 1
# 9 3 7 6 5
sample_df # 원본은 변화가 없다
# var_1 var_2 var_3 var_4 var_5
# a 2 2 1 4 3
# b 4 3 3 7 1
# c 5 4 6 3 5
# d 1 4 5 6 7
# e 4 5 7 8 3
# f 5 4 8 9 4
# g 7 5 2 0 6
# h 8 8 1 7 8
# i 2 3 5 2 1
# j 9 3 7 6 5DataFrame.count( ) : 변수(col)별 데이터 개수
sample_df.count()
# var_1 10
# var_2 10
# var_3 10
# var_4 10
# var_5 10DataFrame.sum( ) : 변수(col)별 합
sample_df.sum()
# var_1 47
# var_2 41
# var_3 45
# var_4 52
# var_5 43DataFrame.mean( ) : 변수(col)별 평균
sample_df.mean()
# var_1 4.7
# var_2 4.1
# var_3 4.5
# var_4 5.2
# var_5 4.3DataFrame.media( ) : 변수(col)별 중위값
sample_df.median()
# var_1 4.5
# var_2 4.0
# var_3 5.0
# var_4 6.0
# var_5 4.5DataFrame.var( ) : 변수(col)별 분산
sample_df.var()
# var_1 7.122222
# var_2 2.766667
# var_3 6.722222
# var_4 8.177778
# var_5 5.566667DataFrame.std( ) : 변수(col)별 표준편차
sample_df.std()
# var_1 2.668749
# var_2 1.663330
# var_3 2.592725
# var_4 2.859681
# var_5 2.359378DataFrame.aggregate( ) : 변수(col)별 통계값을 모아서 보기
sample_df.aggregate(['sum', 'mean'])
# var_1 var_2 var_3 var_4 var_5
# sum 47.0 41.0 45.0 52.0 43.0
# mean 4.7 4.1 4.5 5.2 4.3
sample_df.aggregate(['var', 'std'])
# var_1 var_2 var_3 var_4 var_5
# var 7.122222 2.766667 6.722222 8.177778 5.566667
# std 2.668749 1.663330 2.592725 2.859681 2.359378DataFrame.groupby('col 명') : 해당 변수(col)에 대하여 그룹화시키고 통계를 구한다
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/iris.csv'
iris = pd.read_csv(file_url)
iris.head()
# iris의 class 변수에는 'versicolor', 'virginica', 'setosa'가 있다 -> 그룹화
iris.groupby('class').mean()
# 모든 setosa의 sepal length 평균, sepal width 평균, petal length 평균, petal width 평균
# 모든 versicolor의 sepal length 평균, sepal width 평균, petal length 평균, petal width 평균
# 모든 virginica의 sepal length 평균, sepal width 평균, petal length 평균, petal width 평균
iris.groupby('class').agg(['count', 'mean']) # 여러 개의 통계 분석을 한 번에 진행
DataFrame['col 명'].unique() : 변수(col)에 중복되지 않는 고유값
DataFrame['col 명'].nunique() : 변수(col)에 중복되지 않는 고유값의 종류 개수
DataFrame['col 명'].value_counts() : 변수(col)에 중복되지 않는 고유값이 총 몇 개씩 있는가
iris['class'].unique()
# array(['versicolor', 'virginica', 'setosa'], dtype=object)
iris['class'].nunique()
# 3
iris['class'].value_counts()
# versicolor 50
# virginica 50
# setosa 50- DataFrame 합치기
# 데이터 불러오기
left_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/left.csv'
right_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/right.csv'
# DataFrame 만들기
left = pd.read_csv(left_url)
# key var_1 var_2
# 0 a 1 1
# 1 b 3 2
# 2 c 4 4
# 3 d 2 3
# 4 e 1 0
right = pd.read_csv(right_url)
# key var_3 var_4
# 0 b 4 3
# 1 c 6 5
# 2 e 3 8
# 3 f 2 7
# 4 g 3 4A.merge(B) : A와 B에 공통으로 있는 col을 자동으로 찾아서(key), 해당 col에 공통으로 있는 값에 대해서만 합친다
공통 col : key (b, c, e)
A.merge(B, on = {'원하는 변수'}) : 특정 변수를 지정해 key로 사용하고 싶을 때
left.merge(right)
# key var_1 var_2 var_3 var_4
# 0 b 3 2 4 3
# 1 c 4 4 6 5
# 2 e 1 0 3 8A.merge(B, how = 'outer') : 데이터 전체를 합치기
left.merge(right, how = 'outer') # 값이 없을 경우, NaN으로 처리
# key var_1 var_2 var_3 var_4
# 0 a 1.0 1.0 NaN NaN
# 1 b 3.0 2.0 4.0 3.0
# 2 c 4.0 4.0 6.0 5.0
# 3 d 2.0 3.0 NaN NaN
# 4 e 1.0 0.0 3.0 8.0
# 5 f NaN NaN 2.0 7.0
# 6 g NaN NaN 3.0 4.0A.merge(B, how = 'left') : 데이터를 합칠 때, A의 key를 기준으로 합치기 (B에서 없는 값은 NaN)
A.merge(B, how = 'right') : 데이터를 합칠 때, B의 key를 기준으로 합치기 (A에서 없는 값은 NaN)
left.merge(right, how = 'left')
# key var_1 var_2 var_3 var_4
# 0 a 1 1 NaN NaN
# 1 b 3 2 4.0 3.0
# 2 c 4 4 6.0 5.0
# 3 d 2 3 NaN NaN
# 4 e 1 0 3.0 8.0A.join(B) : 인덱스를 key로 삼아서 결합
# join은 인덱스를 기준으로 결합하기 때문에, 두 DataFrame에 겹치는 col이 있으면 안된다
# join을 쓰기 위해서는 [key]를 삭제해야 한다
left.drop('key', axis = 1).join(right.drop('key', axis = 1))
# var_1 var_2 var_3 var_4
# 0 1 1 4 3
# 1 3 2 6 5
# 2 4 4 3 8
# 3 2 3 2 7
# 4 1 0 3 4
# 만약 [key]를 기준으로 결합을 하고 싶다면, [key]가 index가 되어야 한다
left = left.set_index('key')
right = right.set_index('key')
left.join(right) # 전체 조인 (합집합)
# var_1 var_2 var_3 var_4
# key
# a 1 1 NaN NaN
# b 3 2 4.0 3.0
# c 4 4 6.0 5.0
# d 2 3 NaN NaN
# e 1 0 3.0 8.0
left.join(right, how = 'inner') # 내부 결합 (교집합)
# var_1 var_2 var_3 var_4
# key
# b 3 2 4 3
# c 4 4 6 5
# e 1 0 3 8
left.join(right, how = 'left')
# var_1 var_2 var_3 var_4
# key
# a 1 1 NaN NaN
# b 3 2 4.0 3.0
# c 4 4 6.0 5.0
# d 2 3 NaN NaN
# e 1 0 3.0 8.0
left.join(right, how = 'right')
# var_1 var_2 var_3 var_4
# key
# b 3.0 2.0 4 3
# c 4.0 4.0 6 5
# e 1.0 0.0 3 8
# f NaN NaN 2 7
# g NaN NaN 3 4pd.concat([A, B]) : 행 기준 데이터 결합
left
# var_1 var_2
# key
# a 1 1
# b 3 2
# c 4 4
# d 2 3
# e 1 0
right
# var_3 var_4
# key
# b 4 3
# c 6 5
# e 3 8
# f 2 7
# g 3 4
pd.concat([left, right]) # left 밑에 right 붙이기 (row 방향)
# var_1 var_2 var_3 var_4
# key
# a 1.0 1.0 NaN NaN
# b 3.0 2.0 NaN NaN
# c 4.0 4.0 NaN NaN
# d 2.0 3.0 NaN NaN
# e 1.0 0.0 NaN NaN
# b NaN NaN 4.0 3.0
# c NaN NaN 6.0 5.0
# e NaN NaN 3.0 8.0
# f NaN NaN 2.0 7.0
# g NaN NaN 3.0 4.0
pd.concat([left, right], axis = 1) # left 옆에 right 붙이기 (col 방향)
# var_1 var_2 var_3 var_4
# key
# a 1.0 1.0 NaN NaN
# b 3.0 2.0 4.0 3.0
# c 4.0 4.0 6.0 5.0
# d 2.0 3.0 NaN NaN
# e 1.0 0.0 3.0 8.0
# f NaN NaN 2.0 7.0
# g NaN NaN 3.0 4.0'머신러닝' 카테고리의 다른 글
| 06. 지도 학습 (분류, 회귀) - K-최근접 이웃 (KNN) : 와인 등급 예측하기 (0) | 2023.01.22 |
|---|---|
| 05. 지도 학습 (분류) - 로지스틱 회귀 : 타이타닉 생존자 예측하기 (0) | 2023.01.21 |
| 04. 지도 학습 (회귀) - 선형회귀 : 보험료 예측하기 (0) | 2023.01.21 |
| 03. Numpy (0) | 2023.01.14 |
| 01. 머신러닝 시작하기 (0) | 2023.01.02 |


